觀念簡介 使用 StreamDiffusion 在進行影像生成的邏輯,跟一般大家比較常見到的生圖會不太一樣,如果你是有在用 ComfyUI、Stable Diffusion WebUI 的人,StreamDiffusion 的參數設置會有很大的不同。
差異最大的是 Step,大部分一般生圖常用的 step 數量會在20~30左右,而 StreamDiffusion 需要設定的 Step 數極低,大概會落在1~3左右,這也是他可以達到即時生成速度的原因之一。
那導致的就是 Prompt 的表現力不強,用很長很複雜的 Prompt 其中大部分的詞都表現不太出來。畢竟迭代的次數不夠,若是硬要加強 Prompt 的演算權重,只會讓生出來的圖變的糊糊的。這個插件也因此在某個版本之後就拔掉了 Negative Prompt。
當然影像的精緻度也低了不少,有時會出現不太合邏輯的獵奇影像。但這一切都是為了速度上的犧牲!一般可能大家跑圖生個 20 秒到 1 分鐘,但 StreamDiffusion 是給你 1 秒 10 張。
總之在設計生成的時候,每個參數光微調就會帶來巨大影響,不一樣的參考圖、生成步數、每個 Step 的 Image Strength、Prompt 的設計等等都會互相牽引。其中 Prompt 的設計最有趣,因為在精簡的 Prompt 中,多加入一個形容詞或名詞有時就會造成非常大的差異。
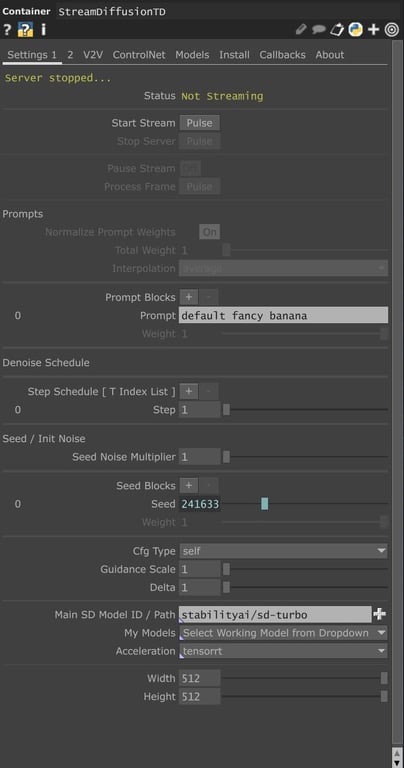
StreamDiffusionTD 基礎操作介紹 那在上一篇的教學中我們已經教大家怎麼在 Install 中建置環境了,今天主要就會聚焦在操作 StreamDiffusion 時最常會使用到的 Setting 1 去做介紹 。
那首先我們可以看到 Prompt 的部分,可以看到有輸入文字的地方,預設是 “default fancy banana”,這邊就是讓你輸入文字指令去控制影像生成的地方。
閃電! 指令的輸入其實有很多眉角和值得深入研究的地方,畢竟他無法表現太長的指令,如何用精簡的指令就達到你想做到的影像生成就有很多小技巧。
例如我今天想要生成一些自然元素,輸入 thunder、fire 等等的詞時,其實蠻常會出現一些 logo、插圖、文字等等的影像,但在這邊又沒有 Negative Prompt,這時候可以有兩種方式,最簡單的一個是,你直接加上 “no text” 在 Prompt 裡,那另一個是加入一些環境的描述和形容詞等,例如 thunder in dark sky、real fire flame 等等,文法不一定要正確,精簡的表達想呈現的內容即可。
但如果要在增加更多的描述,例如他在圖像中的位置、型態等等的就會較難表現出來,我自己使用的經驗是,大概一段 10~15 個單字的句子就是極限了,若要做到更精準的圖像控制,就要使用接下來這個參數了。
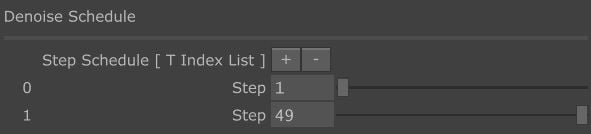
Step Schedule 是有非常多可玩性的設定,在這邊你可以調整影像生成的迭代步數,跟常見的使用ComfyUI、Stable Diffusion WebUI 不同,Step 通常都是讓你打一個數字而已,但這裡增加 Step 的方式是按下「 + 」。
每個 Step 有Image Strength ( 圖像引導強度 ) 的數值去做微調,這個數值會是 1~49 間的整數,在調整時你會發現數值越小 ( 拉桿越靠左 ) 他對於圖像的想像力、指令的表達程度會越高,數值越大 ( 拉桿越靠右 ) 他對參考圖的還原程度會越高。
而 Step 的數量我自己通常最多就是 3~4 個而已,詳細的原因我會在這篇文的後半,比較進階的段落去說明。
調整 Seed 造成的頻閃 Seed 這裡是指生成用的隨機參數,在指令 、參考圖、Seed 三者皆一樣的情況下,會生成出幾乎一模一樣的圖,那你希望增加更多變化與生成的隨機性,你可以考慮讓 Seed 動態變化,但這麼做的壞處是,因為 Seed 的變化會造成影像生成非常大的變動,會讓幀與幀之間失去了連結性,看起來會像一直頻閃的影像而不是一個正在緩慢變化的物件。
Seed Noise Multiplier 可以決定 Noise 的強度,調高可以增加影像變化的創造力與隨機性,但圖像的品質也會略有下降。
長寬指的就是 latent image 的維度大小,也代表著圖像輸出的長寬,在模型可以支援的情況下可以往上調,但調高的同時生成速度當然就會下降,可以自己找平衡,但要注意調整的數值不能亂給,建議都要是 16、32 的倍數等等,不然會出現一些模型運算時矩陣維度不匹配的報錯 ( 後來發現新版本會自己幫你修正成可以跑的數字 )。如果是因為想要增強效能而調低的話,不只是會讓輸出的像素數變低,他還會讓輸出的圖象精緻程度指數等級的下降很多 ,才調降一點點的大小,生圖的品質就會指數級下降。
主因是因為長寬改變不只是限縮了輸出大小,在技術上來說,也是降低了生成圖像的 latent space 大小,生成效果會變很差。打個比方,生成模型就像雕刻藝術家,你給他一顆大塊石頭叫他雕人臉,他可以幫你把表情細節都做得很好,但今天如果石頭變小塊而工具不變,雕刻藝術家會很難把這樣的細節等比例縮小,雕出來的人臉可能連五官都是不清楚的,能發揮的空間會少很多。
CFG type、Guidance Scale、Delta 這三個參數,其中 CFG type 和 Delta 的調整幾乎不影響影像,而 Guidance Scale 則是一調就會讓整個圖像崩壞,所以建議是放著不動就好,在一般生圖上,這些參數是可以去控制影像的生成的,但放在 StreamDiffusion 這樣少步數的生圖流程,要馬沒作用要馬太敏感。
模型的部分,其實除了原生給的 SD-Turbo 外,還可以去下載其他開源的模型來玩,但這個部份我們留到下一篇教學再探討。
那如果你有安裝成功的話,Acceleration 這邊可以開啟 TensorRT 去加速模型,那加速的部分有些特別需要注意的地方,但內容比較進階,這篇文的後半會繼續補充。
建立互動生成筆刷 那瞭解了所有參數的玩法過後,我們可以直接來實現互動筆刷了!
首先我們可以直接去上面連結下載外國大神在 TD 官網提供的資源,這是一個追蹤滑鼠座標的流體模擬 Operator,可以直接用這個當作給 StreamDiffusion 生成的參考圖來源,直接將 Fluid Simulation 接上 StreamDiffusionTD 後,移動滑鼠就能夠完成即時生成筆刷的功能了。
滑鼠座標輸入位置 踩踏的互動方式 那若要改成滑鼠以外的互動方式,只要進入 Fluid Simulation 並看到圖中標記的這個位置,這裡是 Fluid Simulation 的滑鼠座標來源,從這邊將滑鼠座標換成其他你想輸入的例如姿態感測的節點座標、地面或牆面的觸碰位置等等的,就能完成姿態感測、觸碰生成等。
那他有幾個屬性大家可以調整跟玩看看,可以根據你想要生成的影像型態去調整這些參數。
Source force: 濆濺出去的力度,這個數值調大時,你在移動畫筆後停止時會發現,有一部分的顏色會像潑墨一樣繼續往原本的移動方向擴散 Vorticity: 渦度,數值調大會讓畫筆暈染出去的顏色產生旋轉的數量增加、速度變快 ColorDiffuision: 繪畫軌跡留存的時間,數值越大越快消失,雖然滑桿最大只能拉到 1,但可以直接指定更大的數字,讓畫筆的軌跡更快消失, VelocityDiffusion: 數值調的越大,畫筆周圍的旋轉、擴散速度越慢 畫筆顏色的部分也可以調整,在圖像強度夠高的情境下,畫筆顏色也會很大的去影響生成出來的影像色系,更換畫筆顏色在 Color 裡面可以拉一個自訂的漸層色進去。
加上藍色背景來生成海洋 另外大家也可以嘗試加入背景色去豐富情境。總之,若你想要讓影像能盡可能地接近腦中想呈現的樣子,你可以先解構這個影像的色彩比例去做成從參考圖,再使用 Step 的參數去達到影像品質與參考圖還原度的平衡。利用會變化的參考圖、可控的參數,就能達成心中所想的即時互動 AI 影像生成!
把夕陽下的海灘拆分成四個色塊再去生成
進階補充 — Prompt Block Prompt Block 有幾個地方是可以深入去玩的,首先你可以在 Prompt Blocks 這邊按「 + 」,就會多出現一個文字框可以輸入,並且多了 Weight 可以調整,在這邊可以輸入多個不同的 Prompt 並用 Weight 去控制權重,數值越高,Prompt 對於圖像生成的影響就越大。
那在有多個 Prompt 輸入之後,會發現多了 Normalize Prompt Weights、Total Weight、Interpolation 可以調整。在介紹這些數值前先幫大家釐清一個觀念,其實 Prompt Weight 是可以持續往上增加的,但你會發現越增加你的生成圖像會越模糊,原因是因為 Prompt Weight 代表的是你想要在圖像中呈現這個 Prompt 的程度,但因為我們並沒有設定足夠的 Step 讓他演算,所以導致他的影像就會是模糊的,可以再多開幾個 Step 讓他把圖算完整,但相對的生成速度就會減慢。
而 Normalize Prompt Weights 的開啟與否是在控制 Prompt Weight 的總量的,在開啟的時候會把所有的 Prompt Weight 做標準化,讓實際 Prompt Weight 的總影響值不會超過 Total Weight 的值。例如當 Total Weight 設 1 時,我有四個 Prompt 且各自的 Weight 都是 1,那實際上輸入到生成運算中的數值是四個 0.25 的 Prompt Weight。
你也可以這樣思考,若三個 Prompt Weight 都設 1 且關掉 Normalize,表現出來的圖像是跟開啟 Normalize 但把 Total 調到 3 是一樣的。
那 Interpolation 的部分,有 Average 跟 Slerp 可以選擇,他是用來調整 Prompt Weight 做標準化時的算法,兩者使用起來 Slerp 的加權算法,在你動態調整 Prompt Weight 時,影像變化會更平滑一些。
以固定頻率去切換兩個 Prompt 的權重 那這邊可以看到多個 Prompt 與動態調整 Prompt Weight 的玩法,可以去做到兩個完全不同影像做一個融合漸變的過渡!
如果Weight全部設 1,是不是其實跟用頓號打在同一欄是差不多的?不,完全不一樣,多個 block 其實比較像,所有 prompt 都單獨存在時,彼此的互相融合。
更詳細地說,當你只有一個 block 時,假設我是下 real pink flower 的 prompt,他會專注在整張圖去呈現好 real pink flower 的元素,但當你把這些形容詞名詞拆開後,他會注意力分散掉,名詞沒有連在一起成為一個整體而是散落的時候,他就會分散去表現這些提詞,會想要在整張畫面填充粉色的元素、花的元素,但這些元素並不會很好地融合在一起。
Prompt 的部分也可以去思考,在常識來說,這個東西的圖片抓到的容易程度,去思考這張圖生成的可行性例如星空與跟有射手座的星空,絕對是星空更容易生成,效果也會好上許多,細節多的圖像也非常容易出現獵奇、反常的輸出。
Seed Block 的玩法跟 Prompt Block 一樣,利用 Seed Block 的權重切換就能很好地達成生成隨機性,且不會讓影像頻閃。
進階補充 — Step 上限解釋 Step 數量補充 越多的 Step,生成的圖像會越精緻,但每增加一個 Step,生成的 FPS 就會往下掉,只是掉的程度並不會 Step 從 1 變 2,FPS 就會等比從 10 變 5,他變化的速度是一個曲線,而且會隨著 Step 越多,每增加 1 個 Step 掉的 FPS 會越少,但那表示我可以一直往上增加 Step 數量嗎?
在解答前我先敘述一下 StreamDiffusion 之所以可以這麼快速,以及 FPS 不會照迭代數量等比下降的原因。主要是因為他演算法的加速上也有使用了 pipeline 的概念,打個比方,我把生成模型當作是一個數學公式,生成的圖片就是我公式算出來的答案。你可以想像數學公式有分五個步驟,第一張圖可能算到第二步時,下一張圖就準備接著算第一步了,不會等第一張圖五步都跑完。這會導致雖然我好像只要等一步的時間就能拿到下一個答案,但這個答案對應的其實是五步時間前丟給算式的輸入了。
所以增加 Step 數量,雖然他每秒能夠運算出來的圖片張數仍不低,但其實你可能拿到的輸出圖是 1、2秒前的輸入了。那打個具體的比方,我今天增加到了 10 個 Step 在進行運算,StreamDiffusion 的 FPS 大概是 4 左右,大概每 0.25 秒會給我一張圖但其實他每 0.25 秒給我的這張圖其實都是我 2.5 秒前希望他幫我生成的。( 也可以試試用工廠流水線的方式去想像 )
進階補充 — TensorRT 加速問題 TensorRT 實際上他是怎麼做到加速的、原理是甚麼,為了方便大家理解我一樣用比較具體的形容去極簡化他的概念。
第一次開啟 TensorRT 加速時,可以看到指令視窗正在進行一些運算 同樣以數學公式來打比方,TensorRT 加速的概念就是,先預先把這個數學公式可能會產生的計算過程全部寫在黑板上,並且「 簡化 」他,等輸入進來之後就能更快的算出結果。所以你會發現第一次打開這個功能選項的時候,他其實會初始化很久,原因就是因為他正在把算式都條列出來並一一化簡。
從檔案名稱就能知道這是多少個 Step、哪個模型、維度大小的資料夾 但缺點就會是他會多佔了一些硬碟空間去存這些 「 事先列好且簡化過的計算過程 」 。那換模型、添加 lora、增減 Step,都會改變他的「 計算過程 」,導致她會在生成另一個「 事先列好且簡化過的計算過程 」,那這些東西是可以刪除的,位置在 “安裝環境位置\StreamDiffusion\engines\” 的資料夾中,從檔名你就可以判定這是哪個模型跟多少 Step 的預生成資料,如果刪除的話,化簡的過程你會要再重跑一次,所以要自己衡量電腦的空間跟哪些是常用的模型配置。
Refer
⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑⭑
互動研究院 by Luxmin 策劃了一系列關於互動體驗技術、科技藝術與多媒體整合為核心的主題課程、工作坊、社群、聚會,以及 TXRX 互動體驗大會
如有相關專案或其他需求,請洽
luxmin.art